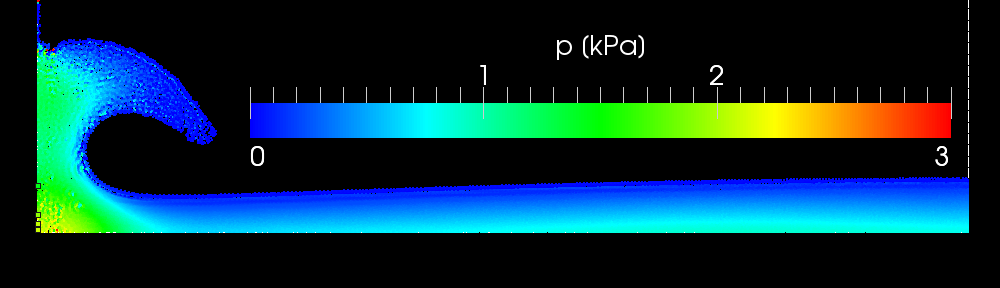
As I reported some weeks ago, I’m working in the code optimization. To do it I implemented the following changes:
- Now all the data (including the output one) is sorted before compute the interactions
- Hence the permutations vectors are not needed anymore in the interactions stage
- Some useless output data have been removed
- The registers pressure have been optimized
Let’s say goodbye to more than 10% of the simulation time!
For the moment the optimized version can be found in the optimization branch of the git repository.
—
P.S. I performed this work with CodeXL by AMD, basically due to NVidia suddenly decided to remove the OpenCL support in the profiler in CUDA 5.
NVidia is expending a lot of resources trying to destroy OpenCL, while AMD is beating them in the hardware side (the real world).
I just hope NVidia people change it’s direction before they reach the final which are deserving.
Also CodeXL is free!
